BiRefNet vs U2Net vs MODNet: Comparing AI Matting Models
An in-depth technical comparison of the three leading AI matting models powering modern background removal tools, with benchmark data and practical recommendations.
If you have ever used an AI-powered background remover, you have likely benefited from one of three leading deep learning architectures: BiRefNet, U2Net, or MODNet. Each takes a fundamentally different approach to the problem of image matting, and each has distinct strengths and weaknesses. In this article, we compare these models across accuracy, speed, memory usage, and real-world performance.
What Is Image Matting?
Image matting is the task of accurately estimating the foreground opacity for every pixel in an image. Unlike binary segmentation, which produces a hard 0-or-1 mask, matting produces a continuous alpha matte where values between 0 and 1 represent partial transparency. This is essential for realistic background replacement, blur effects, and compositing.

Model Architecture Overview
MODNet (2020)
MODNet (Matting Objective Decomposition Network) was designed for real-time portrait matting without any auxiliary input. Its key innovation is decomposing the matting task into three sub-objectives:
- Semantic branch: Predicts the coarse foreground region
- Detail branch: Refines edges and fine structures
- Fusion branch: Combines both outputs into the final matte
This decomposition allows MODNet to run at 30+ FPS on consumer GPUs.
U2Net (2020)
U2Net (U-squared Net) uses a nested U-Net architecture where each stage of the encoder-decoder is itself a U-Net-like structure. This nested design, combined with residual connections (RSU blocks), allows the network to capture both fine-grained details and broad contextual information simultaneously.
BiRefNet (2023)
BiRefNet (Bilateral Reference Network) is the newest architecture. It introduces bilateral reference learning, where the network maintains separate reference encodings for foreground and background regions. This dual-stream approach enables more accurate color disambiguation near object boundaries.
| Feature | MODNet | U2Net | BiRefNet |
|---|---|---|---|
| Year released | 2020 | 2020 | 2023 |
| Parameters | 6.5M | 44.0M | 25.3M |
| Inference speed | 33 FPS | 8 FPS | 22 FPS |
| GPU memory | 1.2 GB | 4.8 GB | 2.9 GB |
| Trimap-free | Yes | Yes | Yes |
| Pretrained weights | Portrait only | General | General + Portrait |
Benchmark Performance
| Metric | MODNet | U2Net | BiRefNet |
|---|---|---|---|
| SAD | 42.1 | 38.8 | 35.2 |
| MSE (x100) | 1.30 | 0.92 | 0.71 |
| Grad | 18.3 | 15.2 | 12.7 |
| Conn | 24.8 | 21.4 | 18.9 |
| Hair IoU | 0.78 | 0.84 | 0.89 |
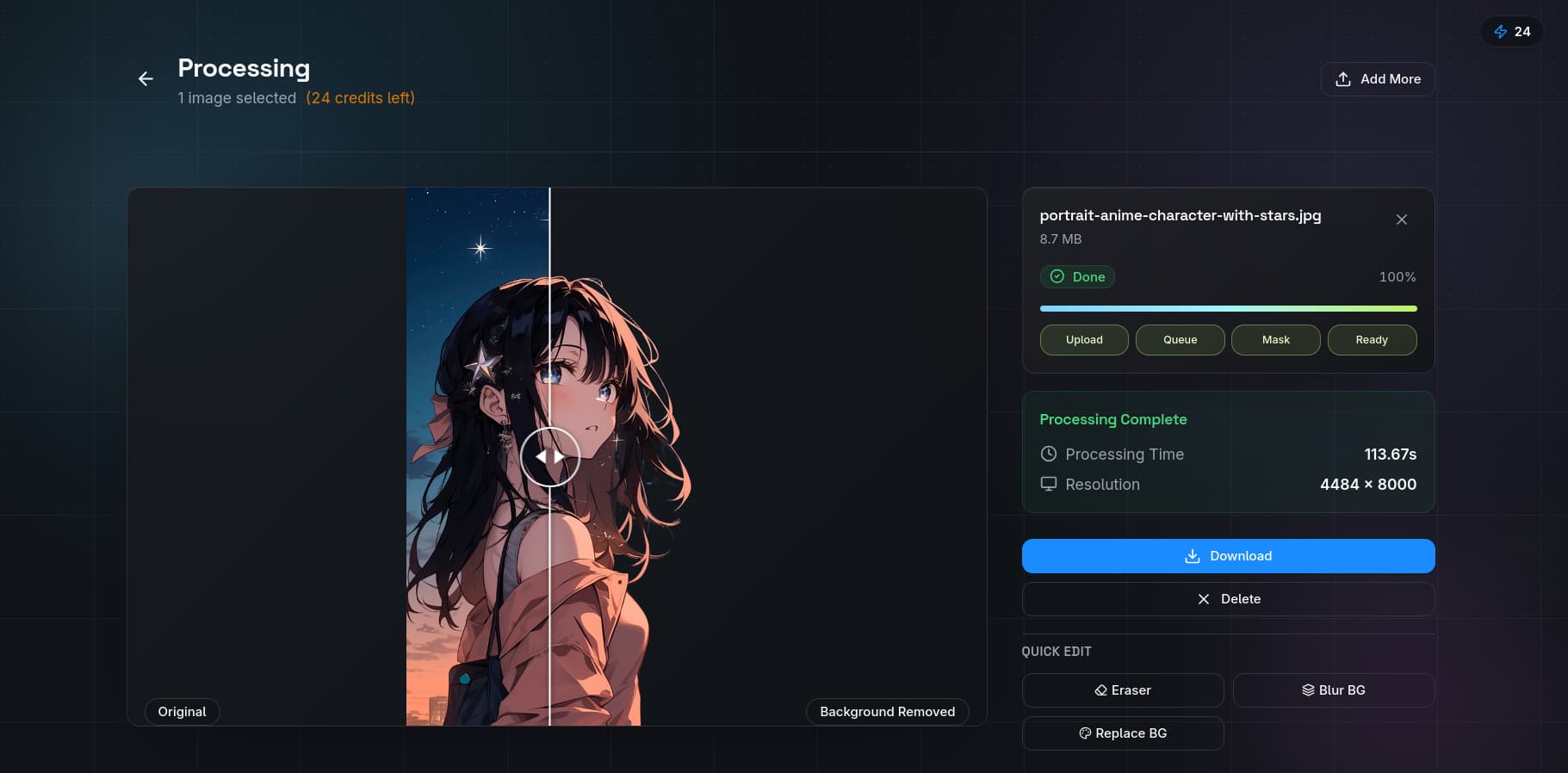
When to Use Each Model
Choose MODNet When: You need real-time processing (30+ FPS), working with portrait photos, limited GPU memory.
Choose U2Net When: You need maximum accuracy on complex subjects, working with non-portrait subjects (animals, products).
Choose BiRefNet When: You want the best overall accuracy, processing high-resolution images, working with transparent or semi-transparent objects.
Integration with QuickBG
Our background remover uses all three models in a cascade. The system first tries MODNet for speed. If the confidence score is below a threshold, it falls back to BiRefNet. U2Net is used as the final refinement stage for complex edges.
Other tools like crop, resize, adjust, sharpness, and converter also leverage these models.
Visit the FAQ for more technical details or the about page to learn about our approach.